Spark’s annoying bug
Before to start… herea are some imports:
import pyspark.sql.functions as F
from pyspark.sql.functions import col as c
from pyspark.sql.types import StringType,FloatType, IntegerType
Pain! I’ve lost almost one week of work (ish, because I’ve already finished all the stuff I needed to do, the thing is I’m going from samples to work with the real data). The thing is: the partition column of the table that I’m working with is a date. Dates usually have an inherent problem in pySpark, because python doesn’t like the spark’s date format and gets confused when comparing the months of both. Nevertheless, if you want to compare the full date, everything seems to work fine. For example, in my case I want to use only the latest date from the table. So, if I get the latest date in the following way:
dates = [i.data_date for i in ifrs9_df.select("date_column").distinct().collect()]
dates.sort()
date = dates[-1]
And then proceed to filter my df by that date like this:
date_cond = c("date_column") == date
ifrs9_df_filtered = df.filter(date_cond)
Everything works and we are happy forever. Unless, you have more than one partition by month. In my case, I have two partitions for March, two for June and one for every other month. So if I try to filter my data like this:
date_cond = (F.year(c("date_column")) == date.timetuple().tm_year) & (F.month(c("date_column")) == date.month)
ifrs9_df_filtered = df.filter(date_cond)
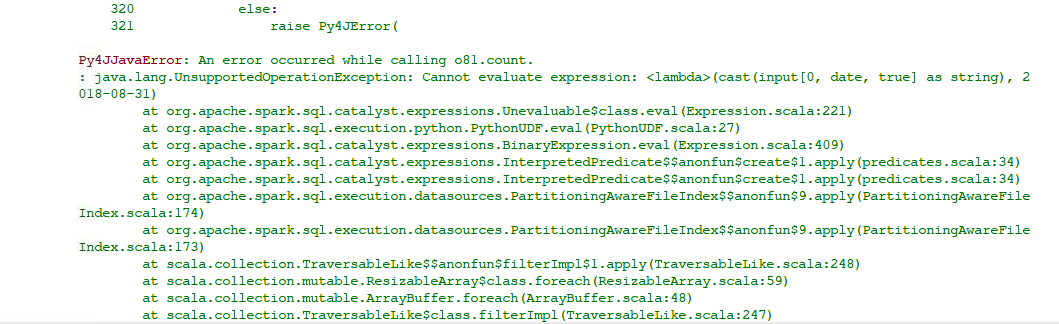
As soon as I proceed to check if the DF is empty or to try to check if it is empty via an assertion (assert (len(df.limit(10).collect()) == 10), “The data frame for this month is Empty”). I get an error message:

This seems to be happening due to an incompatibility between spark and pyhton’s date formats. It seems like this, because, something pretty weird is that this only happens when comparing, if you group data by month and year like this:
count_date_df = df.groupBy(
F.year(c("date_column")), F.month(c("date_column"))).count().orderBy(
F.year(c("date_column")),F.month(c("date_column")))
There is not any problem at all O.o.
So, given Spark and python incompatibilities I thought the “best” way to go was to use an UDF to parse both dates to be compared into strings. I’m going to omit my udf that recieves two strings and only show how I declared it like an UDF:
compare_date_udf = F.udf(lambda a,b: compare_date(a,b), IntegerType())
Now, if I define my latest date as previously -but casting it to string-, make a new column with my date casted as well, and pass both to the UDF, everything seems fine until I call an RDD dependent action such as df.count():
ifrs9_curr_df_a = df.select('*',
c("date_column").cast(StringType()).alias("date_str")
).select(select_group)
ifrs9_curr_df = ifrs9_curr_df_a.filter( compare_date_udf("date_str",F.lit(date)) == 1)
In order to solve this problem, given the Spark’s major bug 20530, you need to add a cache after the variables selection (i.e. before filtering) as follows:
ifrs9_curr_df_a = df.select('*',
c("date_column").cast(StringType()).alias("date_str")
).select(select_group).cahe()
ifrs9_curr_df = ifrs9_curr_df_a.filter( compare_date_udf("date_str",F.lit(date)) == 1)
It will work, however it will make a process that should take 1.3min (using date_cond = c(“date_column”) == date) to complete last about 3.3hours. It may worth it but it is pretty inefficient.
After exhaustive proofreadings and tests all the problem seems to be derived of using an assertion to check if the filtered df is empty:
´´´python def is_empty(df): “”” Checks if a data frame is empty :param df: Spark data frame :return: None “”” print(“”) assert (df.rdd.take(5) ), “The data frame for this month is Empty” #assert (len(df.limit(10).collect()) == 10), “The data frame for this month is Empty” #assert (df.rdd.isEmpty() == False), “The data frame for this month is Empty” ´´´
*If you avoid doing any of these assertions, all the code may run, even if you use F.year(c(“date_column”)), F.month(c(“date_column”)) as the date condition to filter instead of the udf O.o. Moreover, if you use *date_cond = (F.year(c(“date_column”)) == date.timetuple().tm_year) & (F.month(c(“date_column”)) == date.month) it is much faster tha passing through the UDF with the cache (1min 20 s vs aprox 3hrs
So, briefly…
The problem: It is a pain in the #$$ to filter the column used for parquet partition
Why?: There is a major bug in Spark
How to solve it? Using a cache right before applying the filter. It will be pretty slow, though. So, my advice would be to avoid doing that assertion and to save a count in a variable and check that it is not zero instead.